Software
ZITADEL is built with two essential patterns. Event Sourcing (ES) and Command and Query Responsibility Segregation (CQRS). Due to the nature of Event Sourcing ZITADEL provides the unique capability to generate a strong audit trail of ALL the things that happen to its resources, without compromising on storage cost or audit trail length.
The combination of ES and CQRS makes ZITADEL eventual consistent which, from our perspective, is a great benefit in many ways. It allows us to build a Source of Records (SOR) which is the one single point of truth for all computed states. The SOR needs to be transaction safe to make sure all operations are in order. You can read more about this in our ES documentation.
Each ZITADEL binary contains all components necessary to serve traffic From serving the API, rendering GUI's, background processing of events and task. This All in One (AiO) approach makes operating ZITADEL simple.
Software Structure
ZITADELs software architecture is built around multiple components at different levels. This chapter should give you an idea of the components as well as the different layers.
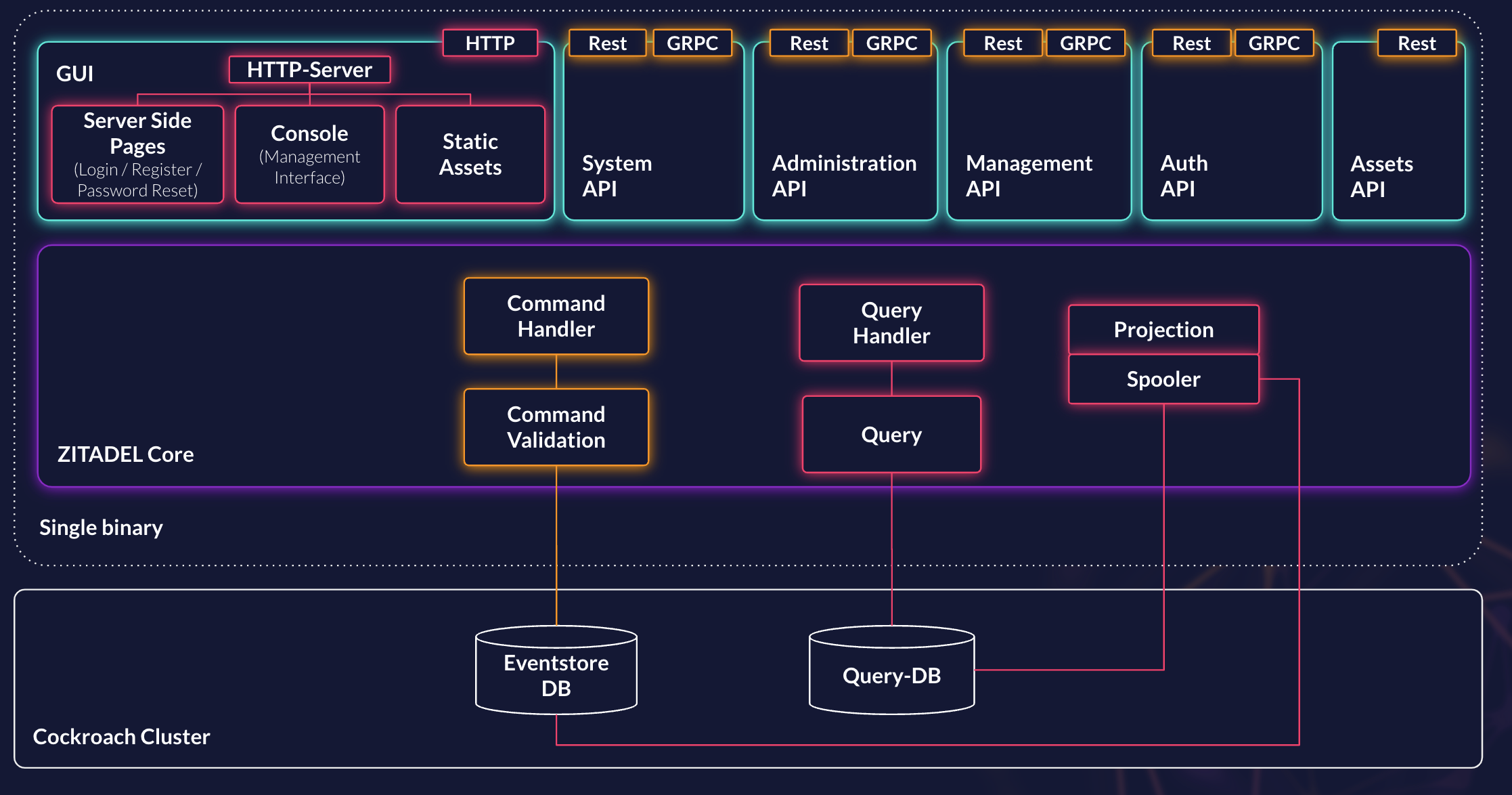
Service Layer
The service layer includes all components who are potentially exposed to consumers of ZITADEL.
HTTP Server
The http server is responsible for the following functions:
- serving the management GUI called ZITADEL Console
- serving the static assets
- rendering server side html (login, password-reset, verification, ...)
API Server
The API layer consist of the multiple APIs provided by ZITADEL. Each serves a dedicated purpose. All APIs of ZITADEL are always available as gRCP, gRPC-web and REST service. The only exception is the OpenID Connect & OAuth and Asset API due their unique nature.
- OpenID Connect & OAuth - allows to request authentication and authorization of ZITADEL
- SAML - allows to request authentication and authorization of ZITADEL through the SAML standard
- Authentication API - allow a user to do operation in its own context
- Management API - allows an admin or machine to manage the ZITADEL resources on an organization level
- Administration API - allows an admin or machine to manage the ZITADEL resources on an instance level
- System API - allows to create and change new ZITADEL instances
- Asset API - is used to upload and download static assets
Core Layer
Commands
The Command Side has some unique requirements, these include:
- Transaction safety is a MUST
- Availability MUST be high
When we classify this with the CAP theorem we would choose Consistent and Available but leave Partition Tolerance aside.
Command Handler
The command handler receives all operations who alter a resource managed by ZITADEL. For example if a user changes his name. The API Layer will pass the instruction received through the API call to the command handler for further processing. The command handler is then responsible of creating the necessary commands. After creating the commands the command hand them down to the command validation.
Command Validation
With the received commands the command validation will execute the business logic to verify if a certain action can take place. For example if the user really can change his name is verified in the command validation. If this succeeds the command validation will create the events that reflect the changes. These events now are being handed down to the storage layer for storage.
Events
ZITADEL handles events in two ways. Events that should be processed in near real time are processed by a in memory pub sub system. Some events hand be handled in background processing for which the spooler is responsible.
Pub Sub
The pub sub system job is it to keep a query view up-to-date by feeding a constant stream of events to the projections. Our pub sub system built into ZITADEL works by placing events into an in memory queue for its subscribers. There is no need for specific guarantees from the pub sub system. Since the SOR is the ES everything can be retried without loss of data. In case of an error an event can be reapplied in two ways:
- The next event might trigger the projection to apply the whole difference
- The spooler takes care of background cleanups in a scheduled fashion
The decision to incorporate an internal pub sub system with no need for specific guarantees is a deliberate choice. We believe that the toll of operating an additional external service like a MQ system negatively affects the ease of use of ZITADEL as well as its availability guarantees. One of the authors of ZITADEL did his thesis to test this approach against established MQ systems.
Spooler
The spoolers job is it to keep a query view up-to-date or at least look that it does not have a too big lag behind the Event Store. Each query view has its own spooler who is responsible to look for the events who are relevant to generate the query view. It does this by triggering the relevant projection. Spoolers are especially necessary where someone can query datasets instead of single ids.
Each view can have exactly one spooler, but spoolers are dynamically leader elected, so even if a spooler crashes it will be replaced in a short amount of time.
Projections
Projections are responsible of normalizing data for the query side or for analytical purpose. They generally work by being invoked either through a scheduled spooler or the pub sub subscription.
When they receive events they will create their normalized object and then store this into the query view and its storage layer.
Queries
The query side is responsible for answering read requests on data. It has some unique requirements, which include:
- It needs to be easy to query
- Short response times are a MUST (80%of queries below 100ms on the api server)
- Availability MUST be high, even during high loads
- The query view MUST be able to be persisted for most request
When we classify this with the CAP theorem we would choose Available and Performance but leave Consistent aside
Query Handler
The query handler receives all read relevant operations. These can either be query or simple getById calls.
When receiving a query it will proceed by passing this to the repository which will call the database and return the dataset.
If a request calls for a specific id the call will, most of the times, be revalidated against the Event Store.
This is achieved by triggering the projection to make sure that the last sequence of a id is loaded into the query view.
The query side has the option to dynamically check the Event Store for newer events on a certain id to make sure for consistent responses without delay.
Query View
The query view is responsible to query the storage layer with the request from the command handler. It is also responsible to execute authorization checks. To check if a request is valid and can be answered.
Storage Layer
As ZITADEL itself is built completely stateless only the storage layer is needed for storing things. The storage layer of ZITADEL is responsible for multiple things. For example:
- Distributing data for high availability over multiple server, data centers or regions
- Guarantee strong consistency for the command side
- Guarantee good query performance for the query side
- Ability to store data in specific data centers or regions for data residency (This is only supported with CockroachDB Cloud or Enterprise)
- Backup and restore operation for disaster recovery purpose
ZITADEL currently supports CockroachDB as first choice of storage due to its perfect match for ZITADELs needs. PostgreSQL support is currently in beta.